Ergo and The Autolykos Consensus Mechanism: Part II
June 20, 2022

Last week, we introduced an in-depth exploration of Ergo’s Autolykos consensus mechanism. With this article, we complete the second part of that discussion and dive into further details. Before reading this document, it is recommended that readers take a look at Part I.
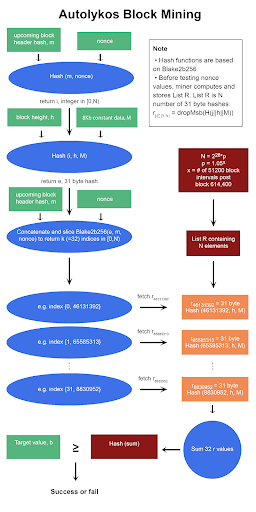
As a reminder, here are the block mining and hash function pseudocodes.
Autolykos Block Mining Pseudocode

Blake2b256 Based Hash function

Lines 3, 4 – begin while loop and guessing
After calculating list R, the miner creates a nonce guess and enters a loop to test if the nonce ultimately creates an output that is below the given target value.
Lines 5, 6 – seed for generating indexes
Line 5, i = takeRight(8, H(m||nonce)) mod N, produces an integer in [0,N). Algorithm 3 is utilized but with m and the nonce as inputs. Once the hash H(m||nonce) is returned, the 8 least significant bytes are kept and then passed through mod N. As a side note, the highest possible integer value with 8 bytes is 264 – 1, and assuming N = 226, an 8-byte hash mod N will result in the first few digits being zero. The number of zeros in i decreases as N grows.
Line 6 produces e, a seed for index generating. Algorithm 3 is called with inputs i (generated in line 5), h, and M. Then, the most significant byte of the numeric hash is dropped, and the remaining 31 bytes are kept as value e. It should also be noted that value e can be retrieved from list R instead of being computed since e is an r value.
Line 7 – index generator
Element index J is created using Algorithm 6 with inputs e, m, and nonce. Function genIndexes is a pseudorandom one way that returns a list of k (=32) numbers in [0,N).
genIndexes function

There are a couple of extra steps that are not shown in the pseudocode such as a byteswap. The creation and application of genIndexes can be explained via the following example:
GenIndexes(e||m||nonce)...
hash = Blake2b256(e||m||nonce) = [0xF963BAA1C0E8BF86, 0x317C0AFBA91C1F23, 0x56EC115FD3E46D89, 0x9817644ECA58EBFB]
hash64to32 = [0xC0E8BF86, 0xF963BAA1, 0xA91C1F23, 0x317C0AFB, 0xD3E46D89 0x56EC115F, 0xCA58EBFB, 0x9817644E]
extendedhash (i.e., byteswap and concatenate 4 bytes by repeating first 4 bytes) = [0x86BFE8C0, 0xA1BA63F9, 0x231F1CA9, 0xFB0A7C31, 0x896DE4D3, 0x5F11EC56, 0xFBEB58CA, 0x4E641798, 0x86BFE8C0]
The following python code shows the process of slicing the extended hash, returning k indexes. In this example we are assuming h < 614,400, thus N = 226 (67,108,864).
Slicing and mod N[1]
for i in range(8):
idxs[i << 2] = r[i] % np.uint32(ItemCount)
idxs[(i << 2) + 1] = ((r[i] << np.uint32(8)) | (r[i + 1] >> np.uint32(24))) % np.uint32(ItemCount)
idxs[(i << 2) + 2] = ((r[i] << np.uint32(16)) | (r[i + 1] >> np.uint32(16))) % np.uint32(ItemCount)
idxs[(i << 2) + 3] = ((r[i] << np.uint32(24)) | (r[i + 1] >> np.uint32(8))) % np.uint32(ItemCount)
The main takeaway is that slicing returns k indexes which are pseudorandom values derived from the seed, i.e., e, m, and nonce.
return [0x2BFE8C0, 0x3E8C0A1, 0xC0A1BA, 0xA1BA63, 0x1BA63F9, 0x263F923, 0x3F9231F, 0x1231F1C, 0x31F1CA9, 0x31CA9FB, 0xA9FB0A, 0x1FB0A7C, 0x30A7C31, 0x27C3189, 0x31896D, 0x1896DE4, 0x16DE4D3, 0x1E4D35F, 0xD35F11, 0x35F11EC, 0x311EC56, 0x1EC56FB, 0x56FBEB, 0x2FBEB58, 0x3EB58CA, 0x358CA4E, 0xCA4E64, 0x24E6417, 0x2641798, 0x179886, 0x39886BF, 0x86BFE8]
This index can be translated to values in base 10 as it refers to numbers in [0, N). For instance, 0x2BFE8C0 = 46131392, 0x3E8C0A1 = 65585313, 0xC0A1BA = 12624314, and so on. The miner uses these indexes to retrieve k r values.
The genIndexes function prevents optimizations as it is extremely difficult, basically impossible, to find a seed such that genIndexes(seed) returns desired indexes.
Line 8 – sum of r elements given k
Using the index generated in line 7, the miner retrieves the corresponding k (=32) r values from list R and sums these values. This might sound confusing but let’s break it down.
Continuing the example above, the miner stores the following indexes:
{0 | 46,131,392},
{1 | 65,585,313},
{2 | 12,624,314},
{3 | 10,599,011},
…
{31 | 8,830,952}
Given the indexes above, the miner retrieves the following r values from list R stored in memory.
{0 | 46,131,392} → dropMsb(H(46,131,392||h||M))
{1 | 65,585,313} → dropMsb(H(65,585,313||h||M))
{2 | 12,624,314} → dropMsb(H(12,624,314||h||M))
{3 | 10,599,011} → dropMsb(H(10,599,011||h||M))
…
{31 | 8,830,952} → dropMsb(H(8,830,952||h||M))
Note that Takeright(31) operated on a 32-byte hash can also be written as dropMsb – drop most significant byte.
Since the miner already stores list R in RAM, the miner does not need to compute k (= 32) Blake2b256 functions and instead looks up the values. This is a key feature of ASIC resistance. An ASIC with limited memory needs to compute 32 Blake2b256 iterations to get the values that could have been looked up in memory, and fetching from memory takes much less time. Not to mention, an ASIC with limited memory would require 32 Blake2b256 instances physically on die to achieve one hash per cycle, which would require more area and higher costs. It's simple to prove that storing list R in memory is well worth the trade off. Assume the following, a GPU has a hash rate of G = 100MH/s, _N = 226, k = 32, block interval t = 120 seconds, and elements are looked up every 4 hashes. I like to assume that elements are looked up every 4 hashes because, for each nonce guess, multiple elements such as i, J, and H(f) require Algorithm 3, i.e. blake2b hash, instances. We can estimate that each r value will be used, on average, (G * k * t)/(N*4) = 1430.51 times.
Once the 32 r values are looked up, they are summed.
Line 9, 10, 11, 12 – check if hash of sum is below target
The sum of the 32 r values is hashed using Algorithm 3, and if the output is below target b, the PoW is successful, m and nonce are returned to network nodes, and the miner is rewarded in ERG. If the sum hash is above the target, Lines 4 – 11 are repeated with a new nonce.
If you have made it this far, congratulations! After reading all of this information, you should have a good understanding of Autolykos v2! If you would like to see a visual demonstration of Autolykos, please see the graphic at the end of this document. If you would like a video explanation, you can find it here.
ASIC Resistance
We know from Ethereum that ‘memory hard’ algorithms can be conquered by integrating memory on ASICs. Ergo is different but let’s first revise why an ASIC with limited memory is uncompetitive and why a miner needs to store list R. Line 8 of Autolykos block mining deters machines with limited memory. If an ASIC miner does not store list R, they require a lot of cores to generate the 31-byte numeric hashes on the fly. 32 r values cannot be efficiently calculated using a single core loop because an output would only be generated every 32nd hash cycle. Given J, to compute one nonce per hash cycle, at least 32 Blake2b256 instances running dropMsb(H(j||h||M)) are needed. As we mentioned above, this increases die size and cost significantly. It’s clear that storing list R is worthwhile because having 32, or even 16, cores is very expensive. More to the point, reading memory is faster than computing Blake instances every time a nonce is tested.
Let’s see if an ASIC with sufficient memory is competitive because that is more relevant to the discussion. Comparing Ethash and Autolykos, the difference is that Ethash involves N elements when hashing the nonce and header mixes 64 times, whereas Autolykos involves N elements when fetching 32 r values based on indexes generated. For every tested nonce, Autolykos runs about 4 Blake2b256 instances and 32 memory fetches while Ethash runs about 65 SHA-3 like instances and 64 memory fetches. Not to mention, k is currently set at 32 but this value can be increased to retrieve more r values if needed. ASICs that run Ethash have a lot of room to increase SHA3 hashing speed since 65 hashes are completed per tested nonce compared to about 4 on Autolykos. The ratio of memory fetches to hash instances is much greater on Autolykos. For this reason, Autolykos is more memory hard than Ethash since memory bandwidth plays a much larger role compared to hashing speed.
An area where Autolykos optimization could take place is the filling of list R. The filling of list R requires N instances of a Blake2b256 function. N is large and only getting larger, so that’s a lot of hashing. An ASIC could optimize the speed of Blake2b256, yielding more time for block mining since list R is filled sooner. Although this can be done, filling list R requires cycling through [0, N) and a GPU with 32-wide multiprocessors can already fill list R very fast (in seconds). One would need an ASIC with many Blake cores to be significantly faster – again, very expensive, and probably not worthwhile since the bottleneck could become memory write bandwidth (i.e., writing list R to RAM rather than hashing speed).
The last area that can be optimized for Autolykos is memory read/write speed. Ethash ASIC miners have a slightly faster read speed compared to GPUs as the memory is clocked higher without the effect of GPU throttling. However, this difference is pretty insignificant and is expected to become more insignificant as GPUs advance. This is because the memory hardware itself is the same: DRAM. One may question if a faster memory hardware could be utilized whereby memory read and write speed is far quicker… SRAM, for instance, could be an imaginable next step in breaking memory hard algorithms, however, SRAM is not a feasible solution simply because it is less dense.
SRAM on FPGA[2]

The above photo is an FPGA with 8 memory chips on the front, and there are another 8 on the back. The total SRAM memory is only 576MB. Fitting sufficient SRAM on a die won’t work because the SRAM will need to be placed further from the core as it is note dense enough to fit in one layer around the core. This can result in read/write delays because electricity needs to travel longer distances even though the hardware itself is faster. Additionally, to mine Ergo, the memory requirement increases as N increases so fitting sufficient SRAM is not feasible overtime. Thus, SRAM ASICs are not worthwhile exploring even if one had enough cash to spend on SRAM itself.
Blake2b256
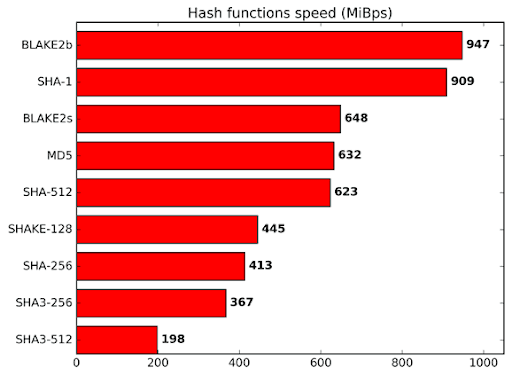
One major difference between an algorithm like Autolykos and others is the use of Blake2b256. This is no coincidence. Blake relies heavily on addition operations for hash mixing instead of XOR operations. An operation like XOR can be done bit by bit whereas addition requires carry bits. Thus, Blake requires more power and core area compared to SHA algorithms, but it is still as secure and in fact, faster. As mentioned on the Blake2 website, “BLAKE2 is fast in software because it exploits features of modern CPUs, namely instruction-level parallelism, SIMD instruction set extensions, and multiple cores.”[3] Thus, while an ASIC can output Blake instances faster, the innate nature of the function limits optimizations by requiring addition and involving features found in CPUs as well as GPUs.
Blake2b speed relative to other hash functions
Conclusion
Autolykos is a great innovation that is a necessary response to combat the rise of PoW-optimized ASIC machines. We hope this 2-part series has helped you to understand Autolykos at a more technical level and why it is more memory hard than Ethash. As Ethereum transitions to a PoS network, there will be a large community of miners looking for a place to direct their hashrate power, and Ergo should be a significant player in attracting those miners.
If you enjoyed this article, the author invites you to check out more content via their Twitter account, @TheMiningApple.
[1] Credit to Wolf9466#9466 on Discord
[2] http://www.ldatech.com/_images/imageGallery/SBM09P-3_front.jpg
[3] https://www.blake2.net/#:~:text=A%3A%20BLAKE2%20is%20fast%20in,of%20the%20designers%20of%20BLAKE2).
Share post

November 28, 2025


November 24, 2025


October 12, 2025

September 30, 2025




August 13, 2025




July 9, 2025

May 12, 2025


December 9, 2024




{kind=link}